
Il fallait au moins une nouvelle puce NVIDIA pour me remotiver à écrire un article. Dans les faits, cette puce est annoncée depuis un petit moment, mais elle vient juste d’être mise en production à Taïwan et devrait arriver dans les serveurs de Microsoft Google et Amazon d’ici le second semestre 2026.
Le timing est donc idéal. Let’s dive in 🤿
Hopper, Blackwell, Rubin
Afin que tout le monde puisse situer où nous en sommes actuellement dans la course à l’intelligence artificielle et plus largement, à la puissance de calcul, il me semble pertinent de vous expliquer sur quelles puces tournent tel modèle. Ça sera probablement plus parlant que de vous sortir des chiffres de données informatiques.
Hopper

La puce Hopper est sortie en 2022. OpenAI — qui détient ChatGPT — n’est pas très transparent sur les puces qu’ils utilisent pour entraîner leur modèle d’intelligence artificielle, mais on peut estimer que GPT-4o a été entraîné sur ces puces si on croise quelques données.
GPT-4o est sortie en mai 2024, soit il y a maintenant 2 ans. Je ne sais pas si vous suivez activement les modèles (vous avez probablement autre chose à faire), mais il est très probable que vous ayez constaté un vrai saut dans les capacités de GPT à cette période précise.
Sinon, pour parler d’un autre modèle, on peut aussi parler de LLama 3 de META en avril 2024, qui est également entraîné sur ces Hopper. Et Mistral Large 3 (🥖).
En bref, c’est une puce un peu datée, mais qui est déjà surprenante.
Pour l’anecdote, c’est la dernière génération que la Chine a le droit d’acheter. Après, pour Blackwell et Rubin, c’est interdit par l’Oncle Sam. Ça explique le retard (relatif) de la Chine par rapport aux États-Unis sur l’IA.
Blackwell

Blackwell est la puce qui est utilisée actuellement pour entraîner la crème de la crème des modèles d’intelligence artificielle.
C’est tout récent que Blackwell a été déployé dans les serveurs, et GPT 5.3 Codex est le premier modèle à avoir été entraîné avec cette puce. Hasard de dingue ; c’est précisément ce modèle qui a relancé la course de qui a la meilleure IA générative, entre Anthropic (Claude) et OpenAI (GPT).
Pour l’anecdote, GPT 5.3 est le premier modèle d’intelligence artificielle s’étant développé lui même. Concrètement, GPT 5.3 écrit du code / fait de l’ingénierie pour améliorer GPT.

Blackwell est déjà une machine de guerre. Elle dispose de 208 milliards de transistors, est gravée en 4 nanomètres (uniquement à Taïwan bien sûr), et embarque 192go de RAM HBM3e. C’est pour cette raison que le prix de la RAM a explosé récemment d’ailleurs.
Si vous ne savez pas ce qu’est de l’HBM, c’est que vous n’avez pas lu mon précédent article sur ce sujet, et que vous devriez aller le lire. 👇🏼
HBM & CoWoS : les nouveaux goulots d’étranglement de l’IA
Et pourquoi le futur se joue en Asie.
C’est en parallèle du déploiement de Blackwell que nous avons commencé à observer une sérieuse mise en place d’IA dite “agentique”, en d’autres termes : l’IA capable d’agir de manière autonome et d’enchaîner des opérations pour atteindre un objectif.
Votre feed Linkedin et X ne parlait plus que de Claude, Clawdbot, Hermès Agent. Eh bien, c’est NVIDIA qui propulse cette nouvelle trend et la rend possible.
Et, évidemment, ce n’est que le début.
Rubin

La puce Rubin est actuellement en production chez TSMC, à Taïwan, et devrait donc arriver chez nos laboratoires d’IA favoris durant le second semestre 2026. Grossomodo, on aura des modèles propulsées par Rubin d’ici la fin d’année 2026 ou début d’année 2027.
Je n’ai donc pas vraiment de comparaison à faire : c’est quelque chose que personne ne connaît encore, mais…
Nous avons déjà les spécifications technique de Rubin, et avec ces derniers, on peut spéculer sur ce qu’apportera concrètement cette génération.
Blackwell avait 208 milliards de transistors, Rubin en aura 336 milliards (une augmentation de 61%).
Gravé en 3 nanomètres (toujours par TSMC). La Rubin Ultra, qui arrivera fin 2027, sera elle gravée en 2nm !
Et pour la RAM, on passe sur la 4ème génération de HBM avec 288go embarquée.
Ce qui, théoriquement, rendra Rubin entre 3 et 5 fois plus puissante que Blackwell (selon ce qu’on mesure). Et Rubin Ultra, qui est annoncée pour 2027, on sera sur un multiple de 14.
There is unlimited demand for intelligence
Je vous parlais plus haut de l’IA agentique débloquée par Blackwell. C’est ici que Rubin devient intéressante.
Imaginons que vous soyez responsable d’une opération de fusion acquisition, et que vous ayez besoin de réaliser les PowerPoints pour présenter le projet à des investisseurs.
L’IA doit mener tout une chaîne d’étape pour réaliser cette tâche. Elle doit lire / analyser les documents en entrée, produire les slides, suivre une charte graphique…
C’est typiquement ce qu’on appelle de l’IA agentique. Le problème, c’est que ce type de tâche consomme infiniment plus qu’une simple discussion avec ChatGPT. Pour une tâche avec 50 étapes, on peut tabler sur un prix 30 fois plus élevé en coût de puissance de calcul.
Rubin débloque précisément la possibilité, pour les labos IA, de réussir à dégager une marge sur ce type de tâche qui coûtent actuellement une fortune.
Rubin divise par 10 le coût par million de tokens pour les data-centers. Ce qui coûtait 100$ auparavant coûte 10$ désormais. Ce qui veut dire que les tâches avec 200 étapes deviennent économiquement viables.
Penser en continu devient accessible & possible pour tout un tas d’entreprise.
On est dans la réduction perpétuelle de prix du token. Plus les puces s’améliore, plus elles sont efficaces, plus elles peuvent accomplir de grandes choses (plus grand qu’un PowerPoint de M&A).
Typiquement pour un développeur informatique, l’IA pourrait actuellement tester 5 approches différentes pour résoudre un problème. La contrepartie, c’est que ça coûterait une fortune à faire tourner, donc votre application limite artificiellement cette possibilité. Donc il vous en donne une, ça fonctionne, fin de l’histoire.
Avec Rubin, on aura de plus en plus de configurations multi-agents. Vous demandez un PowerPoint, il vous en sort 5, vous prenez celui que vous préférez. Vous comparez les prix de différents prestataires ? Il en sort 3 actuellement, il vous en sortira 18 dans un futur proche. C’est que le début.
Il y a une demande infinie pour l’intelligence. Nous sommes en plein “paradoxe de Jervons”.
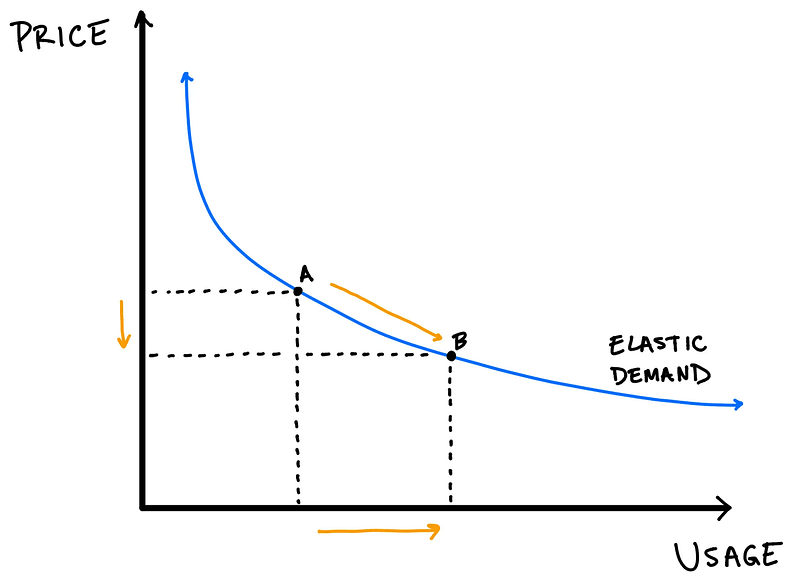
Le paradoxe de Jevons stipule que lorsqu’une technologie devient plus efficace énergétiquement, la consommation totale de cette ressource augmente plutôt que de diminuer, parce que le gain d’efficacité rend son usage moins coûteux, ce qui stimule la demande.
Merci Claude !
La phase 4 arrive
Bon qu’est-ce qu’il raconte ENCORE.
C’est tout simplement une classification de Goldman Sachs des data-centers IA. Vous pouvez trouver le rapport complet ici.
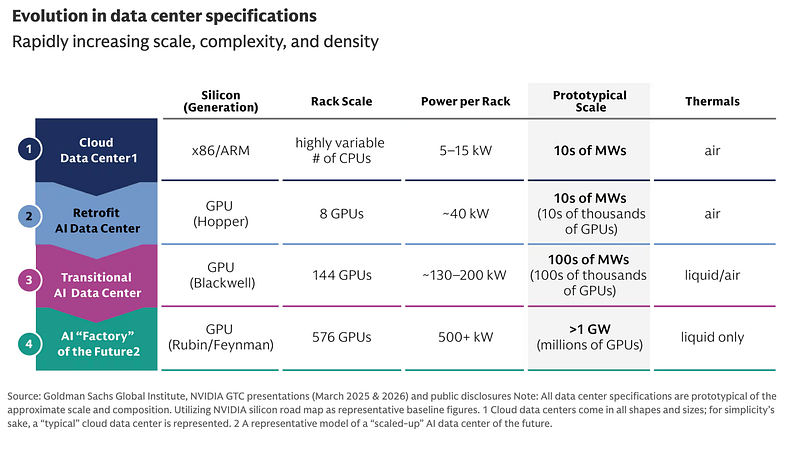
Nous sommes actuellement dans la phase 3. Blackwell se met en route. Nous arriverons dans la phase 4 en 2027. Elle marquera — encore — un bond dans les capacités de l’intelligence artificielle.
Quand GPT est sortie publiquement en 2022, il était entraîné dans des data-centers classiques. Hopper demandait déjà une architecture particulière, mais il a été monté dans des data-centers cloud classique. Blackwell demande déjà une infrastructure particulière incompatible avec des data-centers de stockage. Rubin, je n’en parle même pas, ça chauffe tellement que le refroidissement ne peut que se faire dans du liquide.
On vit une époque absolument fantastique. Libre à vous de vous en saisir. Copiez-collez cet article dans Claude, posez lui des questions. Il n’y a plus aucune limite dans ce que vous pouvez faire avec un ordinateur et une connexion.
Prenez soin de vous.
Jules