Et pourquoi le futur se joue en Asie.
Re, ça faisait un petit moment.
D’ici quelques semaines, je dois faire une conférence sur la chaîne de valeur de l’intelligence artificielle, et par extension, des semi-conducteurs.
Ainsi, j’en profite pour faire un petit article, pour me rafraîchir la mémoire sur ce que je sais déjà, mais également pour évaluer les nouveaux goulots d’étranglement des semi-conducteurs.
Let’s dive in.
J’ai ça dans les oreilles quand j’écris cet article
Les bases
Reprenons les bases avec ce petit schéma réalisé par mes soins ⤵️
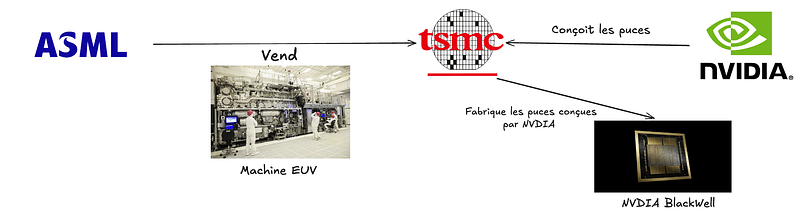
L’histoire est la suivante : tout part d’ASML, entreprise néerlandaise (🇪🇺), qui fabrique les machines EUV, pour lithographie extrême ultraviolet.
Concrètement : ces machines sont probablement parmi les plus complexes jamais inventées par l’Homme. Elles coûtent des centaines de millions unité, et ASML a un monopole quasiment imprenable sur cette technologie.

Ces machines permettent de graver à une finesse de 2 nanomètres, permettant aux puces IA d’être si performante.
👉🏼 Plus la gravure est fine, plus on peut intégrer de transistors sur une même surface de silicium.
👉🏼 Des transistors plus petits nécessitent moins de tension électrique pour basculer entre l’état “0” et “1”.
👉🏼 Comme les composants sont physiquement plus proches, les électrons parcourent des distances plus courtes.
Ces machines, ASML les vend à TSMC, le géant taïwanais des semi-conducteurs.
TSMC sait graver des puces à une finesse absurde (2 ou 3 nanomètres), et surtout : à une échelle industrielle.
TSMC ne conçoit pas de puces. Elle détient les usines qui sont capables de les graver, mais elle n’a pas le savoir-faire nécessaire à la conception. Elle récupère donc des commandes de ses clients (NVIDIA, Apple pour ne citer qu’eux), et grave les puces pour eux.
NVIDIA conçoit donc les puces, la Blackwell — génération actuelle ayant servie à entraîner GPT-5.3-Codex — et la Rubin — la génération future, prévue pour cette année.
Ces puces sont les monstres de puissance sur lesquels repose toute l’architecture de l’intelligence artificielle telle que vous la connaissez.
TSMC, NVIDIA ou ASML sont toutes les 3 en situation de monopole, créant le premier goulot d’étranglement de l’intelligence artificielle : si une de ces entreprises est à l’arrêt, tout le monde est à l’arrêt.
Maintenant que les bases sont posés, passons à ce qui nous intéresse aujourd’hui.
High Band Memory — HBM
C’est ici que ça devient intéressant.
Imaginons que votre PC est un artisan. Je vais trouver deux outils dans la boîte à outil de cet artisan : de la RAM et un SSD.
👉🏼 Le SSD, c’est l’immense armoire. On stocke tout dedans, mais c’est loin et lent à ouvrir.
👉🏼 La RAM, c’est son établi. Quand l’artisan décide de construire quelque chose, il sort les pièces de l’armoire et les met sur l’établi. Il peut y manipuler les objets instantanément.
Dans votre PC, votre RAM est disposée sous forme de barette, à quelques centimètres du processeur. Pour un humain, c’est peu, mais pour des données se déplaçant à la vitesse de la lumière, c’est énorme.
D’où l’invention du HBM.
Le HBM, c’est la version boosté de la RAM. Elle équipe les cartes graphiques ultra-puissantes d’NVIDIA, comme la Rubin ou la Blackwell.
Sur un PC classique, vous avez des barrettes de RAM. Si on veut plus de place, il faut agrandir le terrain.
Avec la mémoire HBM des puces IA, on empile les puces les unes sur les autres. C’est un genre de petit gratte-ciel de RAM.
C’est mieux, car la HBM est posée directement sur le support du processeur, donc la distance est quasi nulle, et le débit est infiniment meilleur.
Ceci étant dit, la mémoire HBM est actuellement détenue par un oligopole coréen 🇰🇷.
👉🏼 SK Hynix, le roi actuel : Ils ont été les premiers à croire à la HBM il y a 10 ans. Ils sont aujourd’hui le fournisseur principal de NVIDIA. Ils ont un brevet sur une technique nommée MR-MUF, une résine liquide injectée entre les couches qui dissipe mieux la chaleur.
👉🏼 Samsung : Ils ont eu un peu de retard sur la HBM3e — utilisée pour les puces NVIDIA Blackwell — , mais ils reviennent en force sur la HBM4 qui servira pour la puce Rubin.
On pourrait également citer Micron, concurrent américain, mais il détient moins de part de marché.
Chip-on-Wafer-on-Substrate — CoWoS
Pour faire fonctionner tout ce petit monde, il manque quelque chose.
On en parlait tout à l’heure, dans votre PC, vous avez de la RAM, un processeur et une carte mère.
Le cerveau (processeur) et la mémoire (RAM) sont deux bâtiments séparés dans la petite ville qu’est votre ordinateur. Pour envoyer des données, ils passent par la carte mère.
🤔 Le problème : même à la vitesse de la lumière, cette route est trop longue, étroite et elle consomme de l’énergie.
C’est ici qu’intervient le CoWoS : au lieu de relier les composants par des câbles, TSMC les fusionne sur un seul et même support microscopique.
C’est comme un petit sandwich :
👉🏼 L’étage supérieur (les puces) : On pose le cerveau (la puce NVIDIA) et ses réservoirs de données (la mémoire HBM) juste à côté.
👉🏼 L’étage intermédiaire (Interposer) : C’est la star. Une petite tranche de silicium qui sert de pont ultra-rapide. C’est ici que les données circulent à une vitesse absurde.
👉🏼 L’étage inférieur (Substrat) : C’est la base qui permet de brancher tout ce bloc sur le reste du serveur.
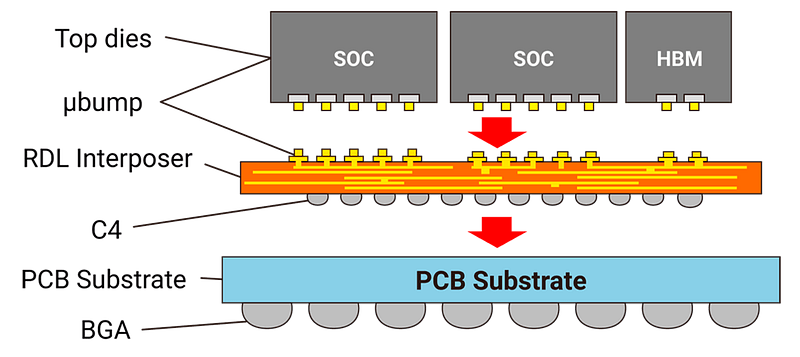
Si nous n’avions pas le CoWoS :
👉🏼 L’IA serait 10 à 20 fois plus lente.
👉🏼 La puce chaufferait, au point que ça serait probablement inutilisable.
👉🏼 Un serveur IA serait infiniment plus grand.
Actuellement, TSMC possède un quasi-monopole sur le CoWoS de haut niveau.
NVIDIA a réservé 60% de la capacité totale de TSMC pour ses puces Blackwell et Rubin, et les autres géants (Apple, AMD, Google, Amazon) se battent pour les 40% de capacité restantes.
La puce Rubin prévoit d’être encore plus difficile à fabriquer à échelle industrielle. Si une seule connexion rate lors de l’assemblage CoWoS, l’ensemble (Puce NVIDIA + mémoire HBM) part à la poubelle. À ce niveau de précision, même un grain de poussière peut tuer une production.
TSMC tourne déjà à plein régime, et on ne construit pas une ligne de fabrication CoWoS facilement. Le carnet de commande d’ASML est déjà plein pour les deux prochaines années, et même si TSMC continue d’ouvrir des usines, il faut des mois pour recevoir, installer et calibrer les machines.
TLDR : NVIDIA fabrique le moteur, le HBM est le réservoir d’essence haut débit, et le CoWoS est le châssis indispensable.
Je voulais faire une partie sur la place du Japon dans l’industrie des semi-conducteurs, mais l’article étant déjà suffisamment dense, je garde ça pour une prochaine fois.
See ya.